
勾引 处男 谷歌再次称霸!伯克利等华东谈主学生技俩,竟成寰宇170+模子竞技场

裁剪:好困勾引 处男
【新智元导读】当初,由UC伯克利、斯坦福、UCSD等高校华东谈主学生发起的AI擂台,如今照旧成为了超越170款模子的大比竞技场!全寰宇的初创公司和科技巨头都在拚命争夺第一的位置。
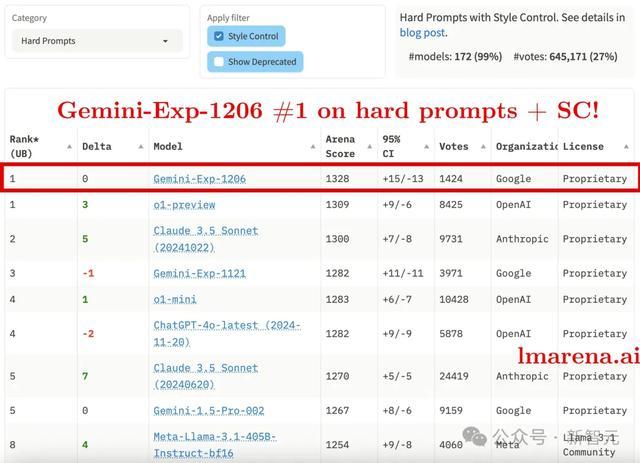
就在谷歌庆祝自家大模子Gemini发布一周年之际,最新版块的gemini-exp-1206也告捷强势纪念!
不仅重新登顶Chatbot Arena总榜第一,况且还在代码智商榜上与o1并驾王人驱。
最新亮点(括号内为与gemini-exp-1121比拟的逾越):
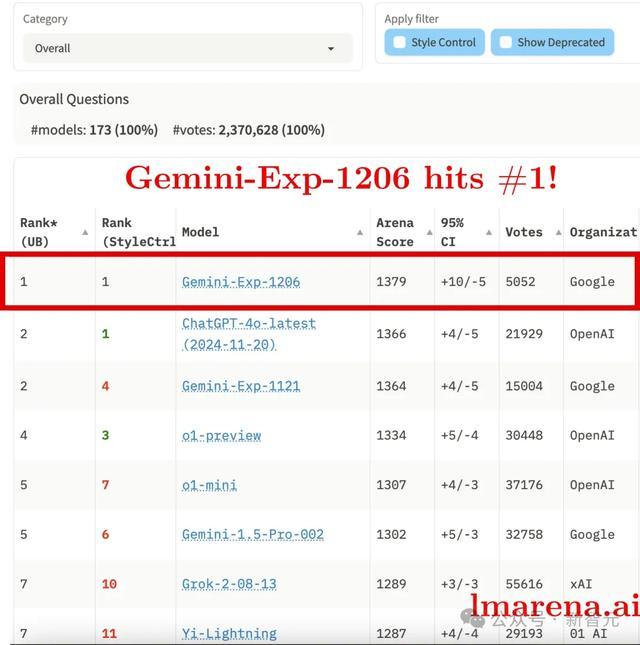
总排名登顶第一(从第2升至第1)
在格调肆意评测中与GPT-4o-1120比肩第一(从第4升至第1)
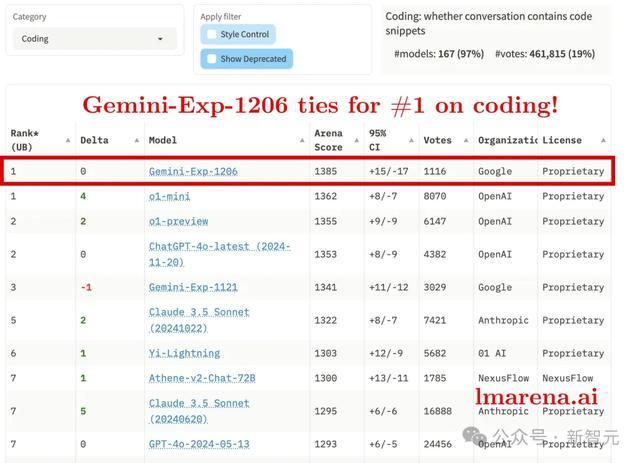
在代码智商榜单与o1比肩第一(从第3升至第1)
在复杂领导词测试中独占鳌头(从第2升至第1)

把握滑动检察
来自UC伯克利、斯坦福、UCSD等高校的学生辘集技俩,激发了AI界的狂热
意想意想的是,当Chatbot Arena在客岁年头刚刚发布时,没东谈主会料想这个由学生主导的技俩,竟会马上成为民众最受戒备的AI系统评测平台。
传统上,AI工夫都是通过高级数学、科学和法律测试来评估的。比拟之下,Chatbot Arena继承的则是一套充足不同的方式——用户提议问题,两个匿名AI模子给出谜底,然后评判哪个回答更好。
最终,这些评分被汇总到一个名次榜上。在这里,OpenAI、谷歌和Meta等硅谷科技巨头会与来自中国和欧洲的初创或者大厂争夺霸主地位。
Meta AI家具惩办总监Joseph Spisak示意:「每家公司都在远程争取登上这个名次榜的榜首。看到几个学生约略产生如斯要紧的影响力勾引 处男,确凿令东谈主赞誉。」

跟着科技公司参加数百亿好意思元押注AI将成为改日几十年的决定性工夫,Chatbot Arena马上走红。
在勾引客户和东谈主才方面,任何率先竞争敌手的上风都可能带来要紧影响,这便是为什么开阔科技高管和工程师像华尔街来去员盯盘同样密切存眷Chatbot Arena。
2023年4月,来自UC Berkeley、斯坦福、UCSD的操办东谈主员郑恻隐、Wei-Lin Chiang、盛颖、张昊推出了Chatbot Arena(LLM竞技场)。
他们使用肖似功绩象棋排名的评分系统,将我方确立的AI工夫与其他开源聊天机器东谈主进行对比。并在只是一周的时期里,就收到了4,700个评分。
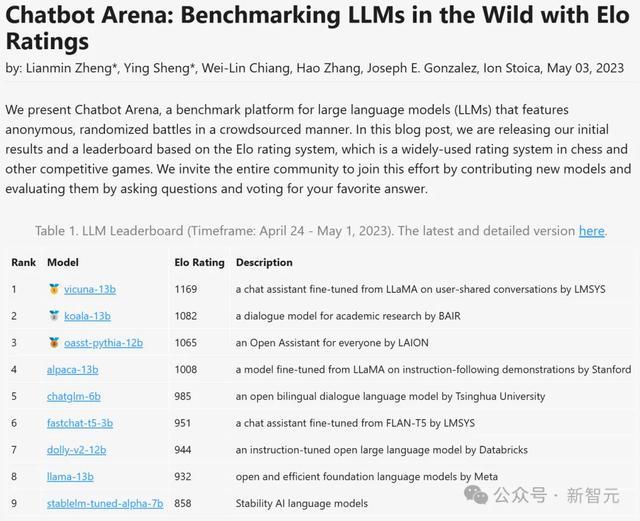
很快,Chatbot Arena就引起了各大AI公司的存眷,它们纷繁苦求将自家工夫纳入排名。
如今,技俩中的模子照旧从最初的9个,发展到了超越170个,并累计得到了200万张选票。
不仅如斯,当今的排名还扩张到了创意写稿、编程和指示执行等挑升类别。
现时,这个技俩由仍在攻读规画机科学博士学位的Anastasios Angelopoulos不息激动。不外,因为他把大部分元气心灵都参加到了这个非谋利的技俩当中,学业进展比较冉冉。
对此,Angelopoulos簸弄谈:「我女一又友从早到晚听到的都是对于Chatbot Arena的事。」

靠「嗅觉」来评分
操办东谈主员示意,跟着时期推移,学术基准测试变得越来越作假用,因为LLM照旧斗争过这些测试题。也便是说,它们照旧提前掌抓了谜底。
Abacus AI的操办主管Colin White示意:「基准测试在刚发布时可能对LLM来说畸形具有挑战性,但当新一代LLM出现后,它们很快就能达到近乎圆善的推崇。」
为此,他们也提议了一种堪称「无法舞弊」的基准——LiveBench,每个月都会更新新的测试题。
无独到偶,MMLU的首创东谈主之一Dan Hendrycks,也启动通过众包方式麇集最具挑战性的问题,用来创建一个全新的基准测试——「东谈主类的临了检会」。

尽管Chatbot Arena继承的一双一双抗方式不会像次序测试那样被舛误攻克,但这种方式并不总能辩论客不雅次序,也无法判断聊天机器东谈主是否严格撤职已考证的事实。这便是为什么一些操办东谈主员将这种身手称为「基于主不雅感受的评估」。
Chatbot Arena的负责东谈主示意,他们恒久对平台的局限性保持盛开立场,并允许用户在检察排名时过滤掉一些格调身分,比如回答的长度和方式等。
Angelopoulos说:「用户的偏好是一个遑急参考观念。毕竟这些测试查询自身就包含主不雅身分。」

微妙的模子
跟着Chatbot Arena的影响力握住扩大,AI爱重者们启动密切存眷新加入的模子,但愿发现一些尚未公开的工夫。
本年5月,一个名为「im-also-a-good-gpt2-chatbot」的微妙模子出当今Chatbot Arena上,独立时激发了强烈的参谋。
效劳解释,这个模子恰是OpenAI其后发布的GPT-4o。
诚然,不惟一OpenAI,马斯克的xAI、Meta和谷歌等,也都会在认真发布之前在Chatbot Arena上测试他们的模子。
11月,谷歌在Chatbot Arena上发布了Gemini工夫的实验版块,随后与OpenAI比肩第一。没过几天,OpenAI通过更新版的GPT-4o暂时率先,但谷歌很快又推出新模子追平了比分。
其时,负责监督Gemini确立的Oriol Vinyals共享了名次榜效劳,还俏皮地配上了三个看戏吃瓜的爆米花神态。
如今,Chatbot Arena麇集的用户响应照旧成为确立者的遑急数据开首。
具体来说,平台按时公开20%的麇集数据——这个比例既能确保数据的实用性,又能防御企业欺诈数据驾御评分系统。
比如,谷歌AI家具司理Kate Olszewska就示意,他们会欺诈这些数据来分析懂工夫的用户是怎样与聊天机器东谈主互动的。
日本学生妹现时,Chatbot Arena照旧招募了十多名孝顺者,他们但愿,能将这个技俩打形成「AI限制的维基百科」。
即便前路漫漫,但团队并莫得贪图将其漂流为谋利性技俩。
参考贵寓:
https://www.wsj.com/tech/ai/the-uc-berkeley-project-that-is-the-ai-industrys-obsession-bc68b3e3勾引 处男