
情色电影下载 GPT-4.1夜深偷袭!OpenAI掏出史上最小、最快、最低廉三大模子,百万token荆棘文

 智东西情色电影下载
智东西情色电影下载
智东西4月15日报谈,刚刚,OpenAI邻接掏出了GPT-4.1系列的三款模子,并称这是其有史以来最小、最快、最低廉的模子系列,且新模子的举座性能发达要优于GPT-4o和GPT-4o mini。
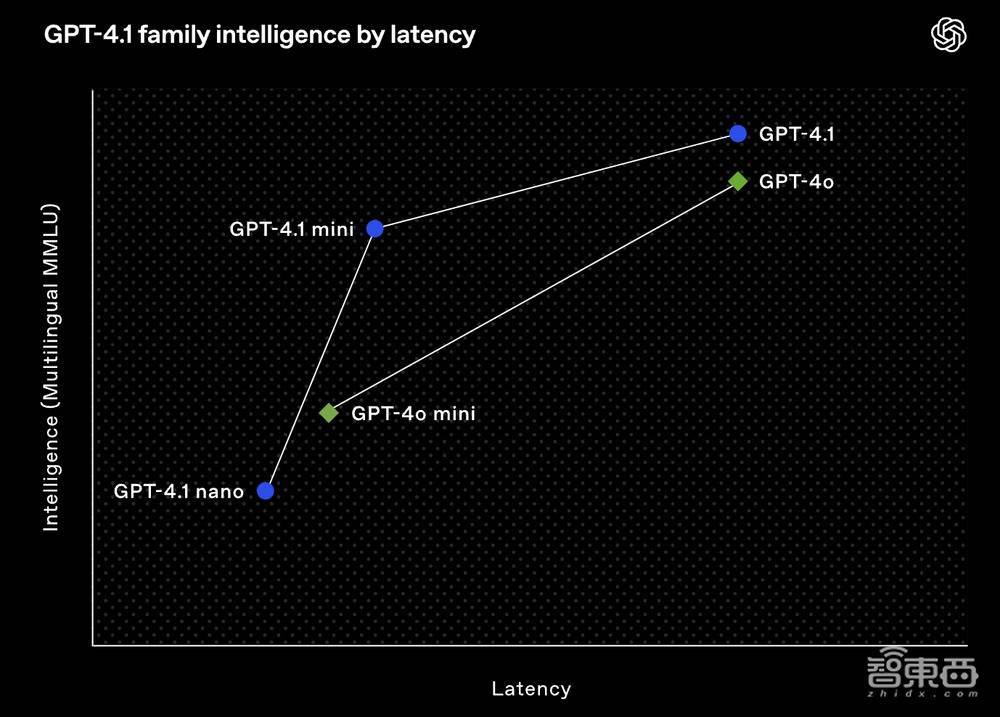
GPT-4.1系列模子包含三个模子:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,荆棘文窗口均达到100万个token,输出token数达到32768个,学问截止日历为2024年6月。OpenAI的基准测试裸露,其在编码、指示着力、长文本联接方面的得分均杰出了GPT-4o和GPT-4o mini。

GPT-4.1系列模子仅通过API提供,现已对所有这个词修复者绽开。OpenAI将运行在API中弃用GPT-4.5预览版,因为GPT-4.1系列模子在好多纰谬能力上提供了相似性能,同期本钱和蔓延更低。GPT-4.5预览版将在本年7月14日关闭。
具体的性能优化皆集于编码、指示着力、长文本联接上:
编码:GPT-4.1在SWE-bench考据测试中得分54.6%,较GPT-4o援救了21.4%,较GPT-4.5援救了26.6%。
指示着力:在Scale的计议指示着力能力预备的MultiChallenge基准测试中,GPT-4.1得分38.3%,较GPT-4o援救了10.5%。
长文本联接:在多模态长文本联接的Video-MME基准测试中,GPT-4.1在无字幕的长文本类别中得分72.0%,较GPT-4o援救了6.7%。
对于对蔓延较为明锐的场景,OpenAI重心提到了GPT-4.1 nano,并称这是其最快、最经济的模子。GPT-4.1 nano基准测试MMLU得分为80.1%,GPQA得分为50.3%,Aider多言语编码得分为9.8%,均高于GPT-4o mini。
GPT-4.1系列模子仅通过API提供,现已对所有这个词修复者绽开。OpenAI将运行在API中弃用GPT-4.5预览版,因为GPT-4.1系列模子在好多纰谬能力上提供了相似性能,同期本钱和蔓延更低。GPT-4.5预览版将在本年7月14日关闭。
OpenAI在博客中提到,性能发达更好、更经济的GPT-4.1系列模子将为修复者构建智能系统和复杂的智能体诈欺拓荒新的可能性。
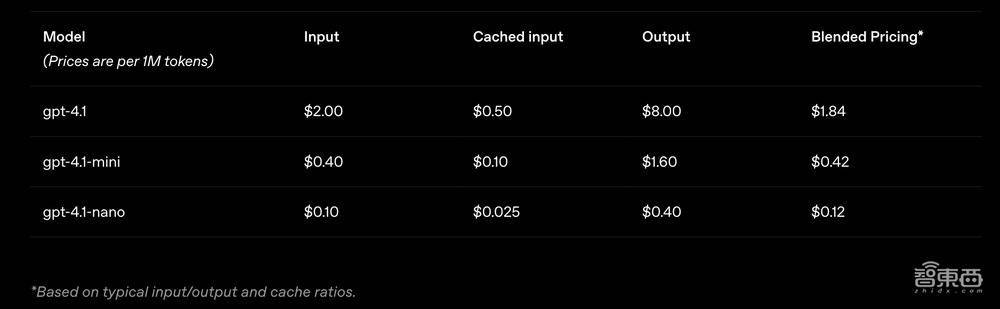
价钱方面,对于中等边界的查询,GPT-4.1的价钱比GPT-4o低26%,对于叠加使用相似荆棘文的查询,OpenAI将教唆缓存扣头从之前的50%提高到了75%。终末,除了次第的每token用度以外,OpenAI不会对长荆棘文苦求零散收费。
GPT-4.1在多种编码任务上的发达优于GPT-4o,包括主动科罚编码任务、前端编码、减少无谓要的裁剪、着力diff要津、确保器用使用的一致性等。
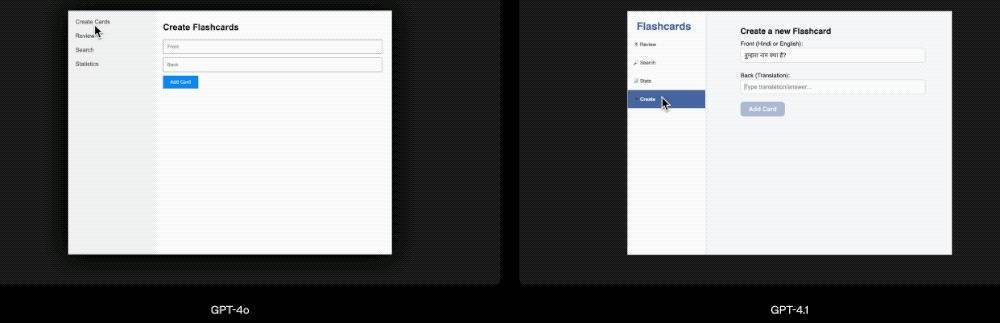
比较于GPT-4o,GPT-4.1不错创立功能更弘远、好意思不雅度更高的Web诈欺,如下图所示的“闪卡”诈欺:
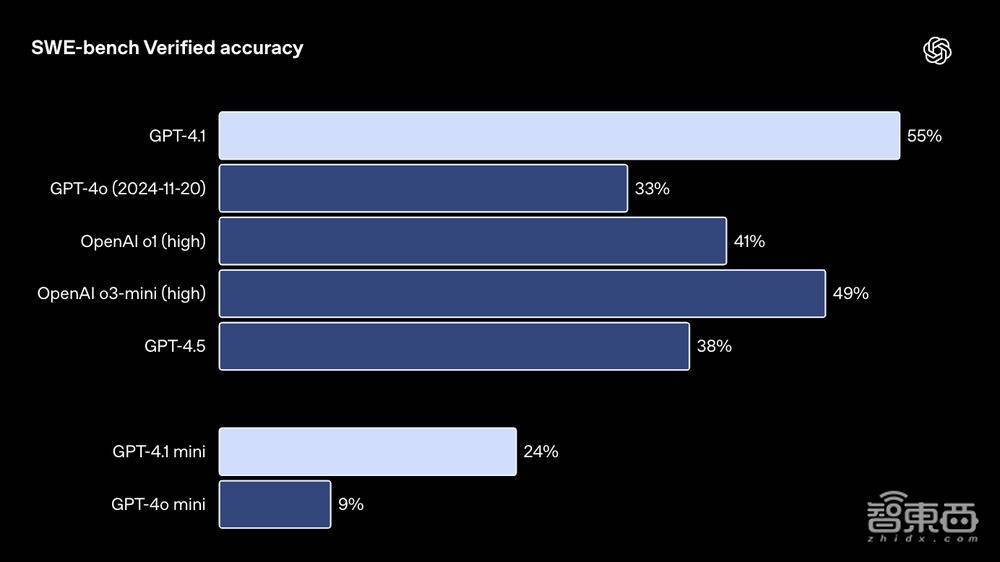
在计议本质宇宙软件工程本领的预备SWE-bench Verified上,GPT-4.1完成了54.6%的任务,GPT-4o为33.2%,这讲解GPT-4.1在探索代码库、完成任务以及生成既可运行又可通过测试的代码方面的能力援救。
▲该测试中,模子会收到一个代码库和问题形色,然后其需要生成补丁来科罚该问题,模子的发达会高度依赖于所使用的教唆和器用。
对于但愿裁剪大文献的API修复者来说,GPT-4.1在多种要津下的代码各别方面愈加可靠。GPT-4.1在多言语各别基准测试Aider中的得分,是GPT-4o的两倍,比GPT-4.5高出8%。
这项评估既测验模子对多样编程言语编码的能力,还有对模子在举座和各别要津下产生变化的能力。OpenAI特意西宾了GPT-4.1以着力各别要津,这使得修复者不错通过模子仅输出鼎新的行来简约本钱和蔓延,而不是重写所有这个词这个词文献。
此外,OpenAI将GPT-4.1的输出token为止增多到32768个,GPT-4o为16384个token,其还冷落使用瞻望输出以减少无缺文献重写的蔓延。
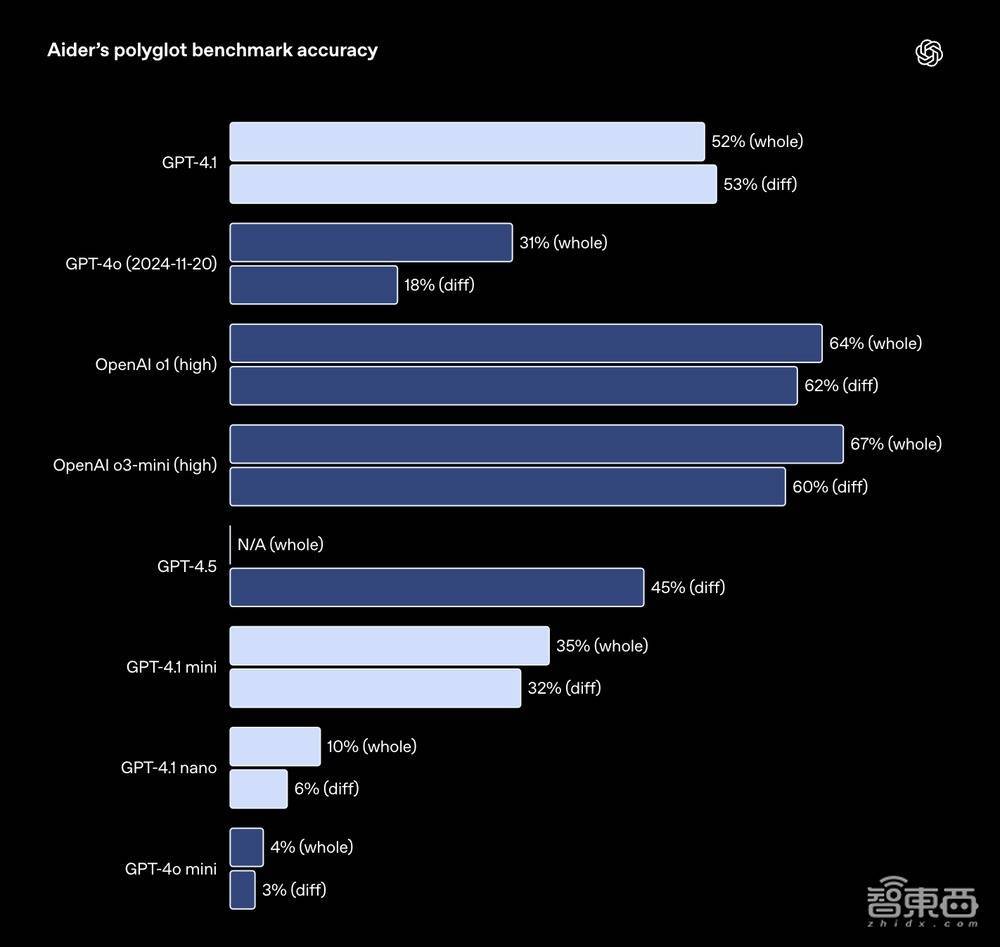
▲在Aider中,模子通过裁剪源文献来科罚Exercism的编码纯属情色电影下载,允许重试一次。
前端编码方面,GPT-4.1能够创立功能更弘远、好意思不雅度更高的Web诈欺。在OpenAI的对比测试中,东谈主工评分员在80%的情况下更景仰GPT-4.1生成的网站,而非GPT-4o生成的网站。
在上述基准测试以外,GPT-4.1不错减少无谓要的裁剪。在OpenAI的里面评估中,代码中的无谓要的裁剪从GPT-4o的9%降至GPT-4.1的2%。
二、着力指示:评估6大纰谬指示性能,多轮当然对话后果比GPT-4o提高10.5%OpenAI修复了一个里面评估系统,用于追踪模子在多个维度和几个纰谬指示着力类别中的性能,包括:
Format following:提供指定模子反应自界说要津的指示,举例XML、YAML、Markdown等;
egative instructions:指定模子应幸免的行径,举例“不要条目用户考虑撑捏”;
Ordered instructions:为模子提供一组必须按给定轨则践诺的指示,举例“领先究诘用户的姓名,然后究诘他们的电子邮件”;
Content requirements:输出包含某些信息的内容,举例“撰写养分揣摸时,持久包含卵白质含量”;
Ranking:以特定风物排序输出,举例“按东谈主口数目排序”。
Overconfidence:若是苦求的信息不能用或苦求不属于给定类别,则相似模子说“我不知谈”或访佛的话。举例:“若是你不知谈谜底,请提供撑捏考虑邮箱。”
OpenAI的博客中提到,这些类别是凭证修复者反馈得出的。在每个类别中,OpenAI将精炼、中等和贫寒教唆进行了细分,GPT-4.1在贫寒教唆方面相对于GPT-4o有权贵援救。
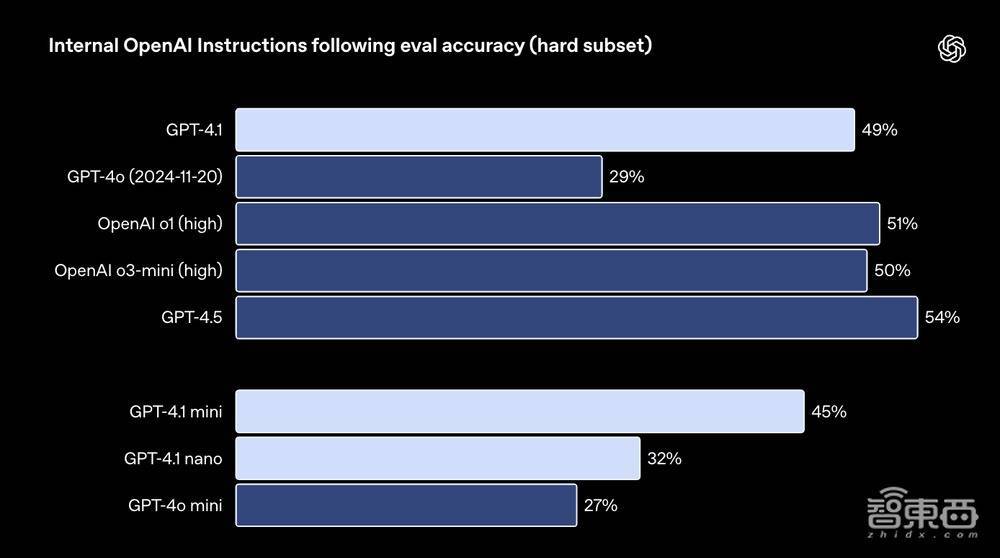
▲GPT-4.1在贫寒教唆方面发达
多轮指示着力对修复者的伏击性在于,模子需要保捏对话的连贯性,并追踪用户之前告诉它的内容。OpenAI西宾GPT-4.1,以使得其能更好地从曩昔的对话信息中索取信息,从而达成更当然的对话。在Scale的MultiChallenge基准中,GPT-4.1比GPT-4o提高了10.5%。
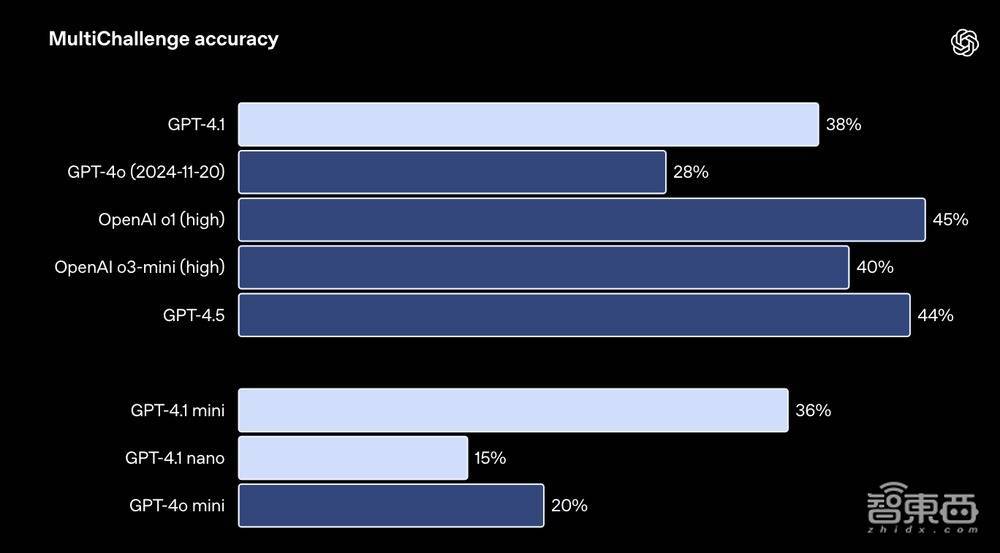
▲GPT-4.1在MultiChallenge中测试收尾
在IFEval测试中,其使用具有可考据指示的教唆,举例,指定内容长度或幸免某些术语或要津。GPT-4.1得分达到87.4%,GPT-4o为81.0%。
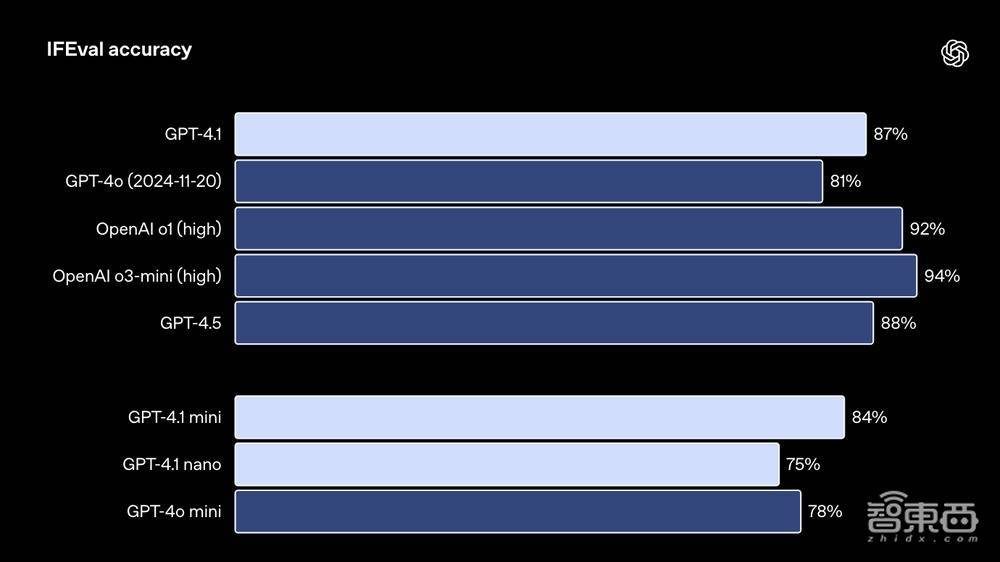
▲GPT-4.1在IFEval中测试收尾
早期测试者指出,GPT-4.1可能更容易联接字面景仰,因此OpenAI冷落修复者不错在教唆中明确具体的指示。
三、长文本联接:适当处理大型代码库、长文档,“大海捞针”也不在话下GPT-4.1系列模子不错处理100万个token荆棘文,此前GPT-4o的荆棘文窗口为128000个。100万个token还是是所有这个词这个词React代码库的杰出8倍之多,因此长荆棘文适当处理大型代码库或大宗长文档。
OpenAI还对GPT-4.1模子进行了西宾,使其能在长和短荆棘文长度中忽略干扰信息,这亦然法律、编码、客户撑捏等多个领域的企业诈欺的纰谬能力。
博客中,OpenAI展示了GPT-4.1在荆棘文窗口内不同位置检索一条荫藏的极少信息(即一根 “针”)的能力,也便是“大海捞针”的能力。
▲OpenAI里面针对GPT-4.1模子的“大海捞针”评估
其收尾裸露,GPT-4.1能够在所有这个词位置以及多样荆棘文长度(直至长达100万个token)的情况下准确检索到这条纰谬信息(“针”)。非论有关细节在输入内容中的位置何如,它都能索取出与现时任务有关的细节。
在骨子使用中,用户频繁需要模子联接、检索多个信息片断,并联接这些片断之间的联系。为了评估这一能力,OpenAI正在开源新的评估器用:OpenAI-MRCR(多轮中枢词识别)。
OpenAI-MRCR不错用来测试模子在荆棘文中找到和分辨多个荫藏得纰谬信息的能力。评估包括用户和助手之间的多轮合成对话,用户条目模子写一篇对于某个主题的著作,举例或“写一篇对于岩石的博客著作”。随后,其会在所有这个词这个词对话荆棘文中插入2、4或8次相似的苦求,模子需要据此检索出对应特定请务实例的回复。
在OpenAI-MRCR中,模子回答的问题,会领有2个、4个或8个散布在荆棘文中的相似教唆词干扰项,模子需要在这些问题和用户教唆之间进行消歧。
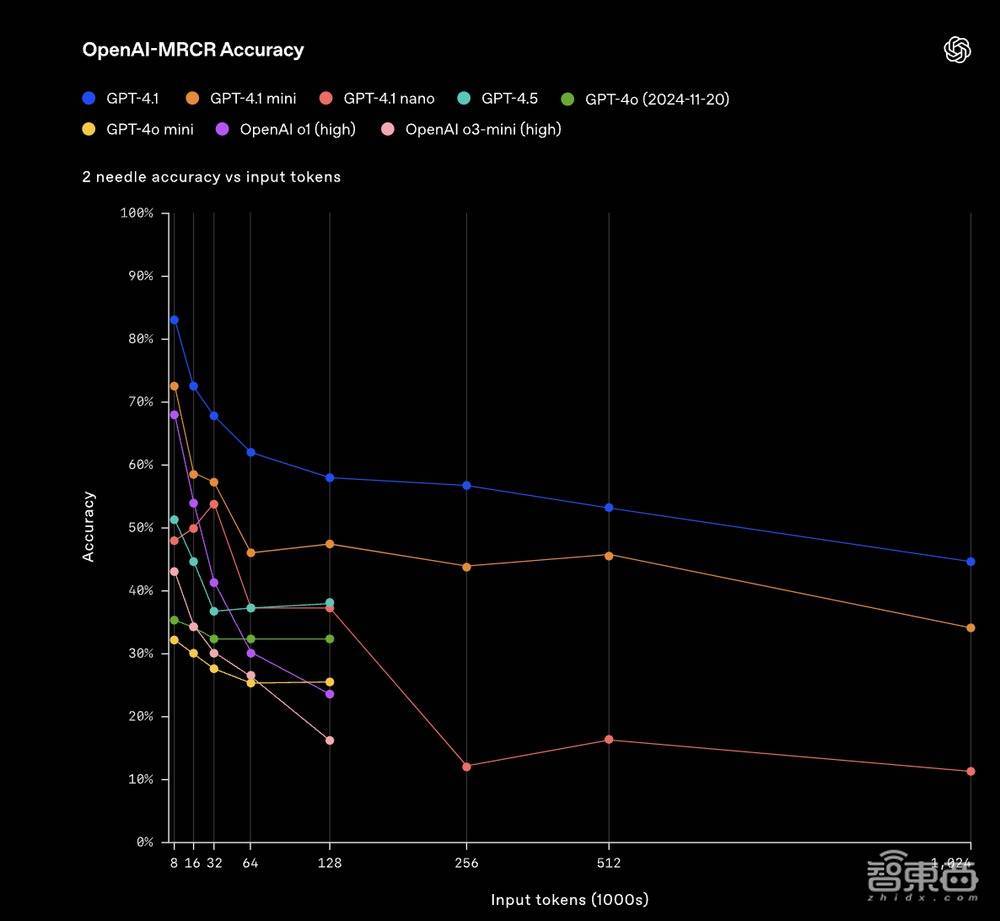
▲在OpenAI-MRCR中,模子回答问题被添加2个干扰项的评估收尾
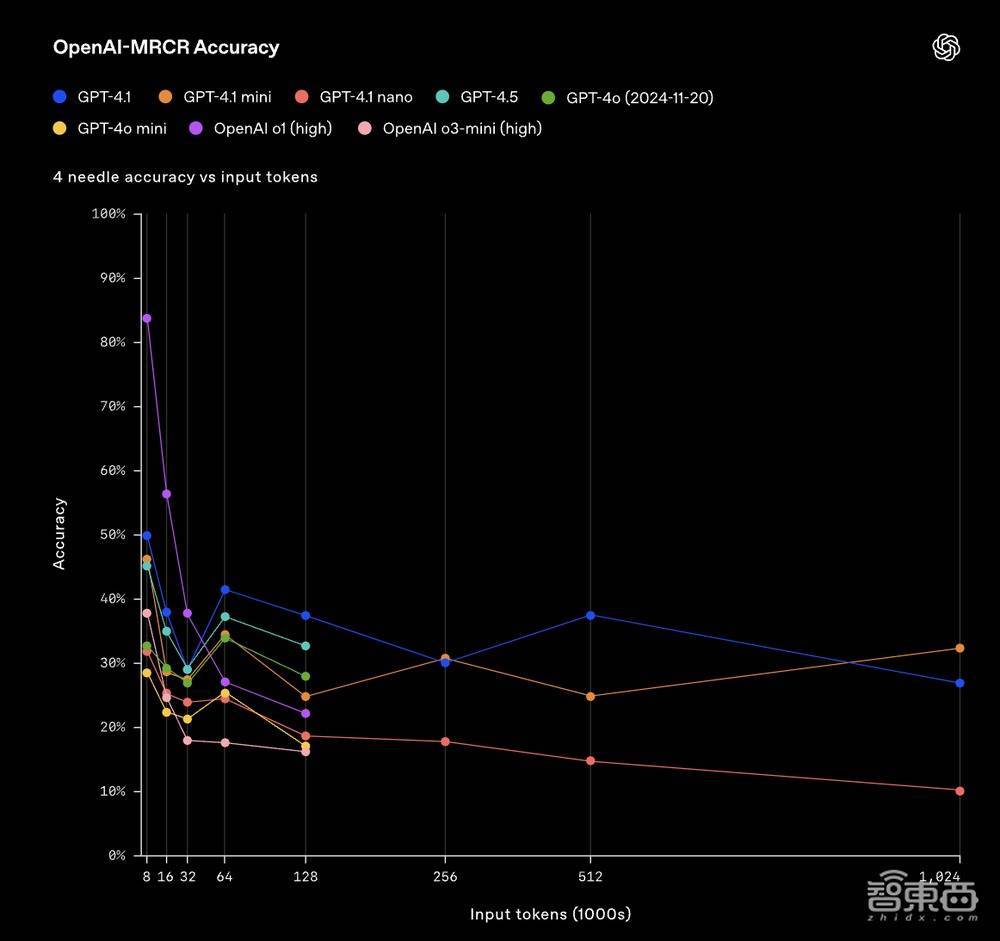
▲在OpenAI-MRCR中,模子回答问题被添加4个干扰项的评估收尾
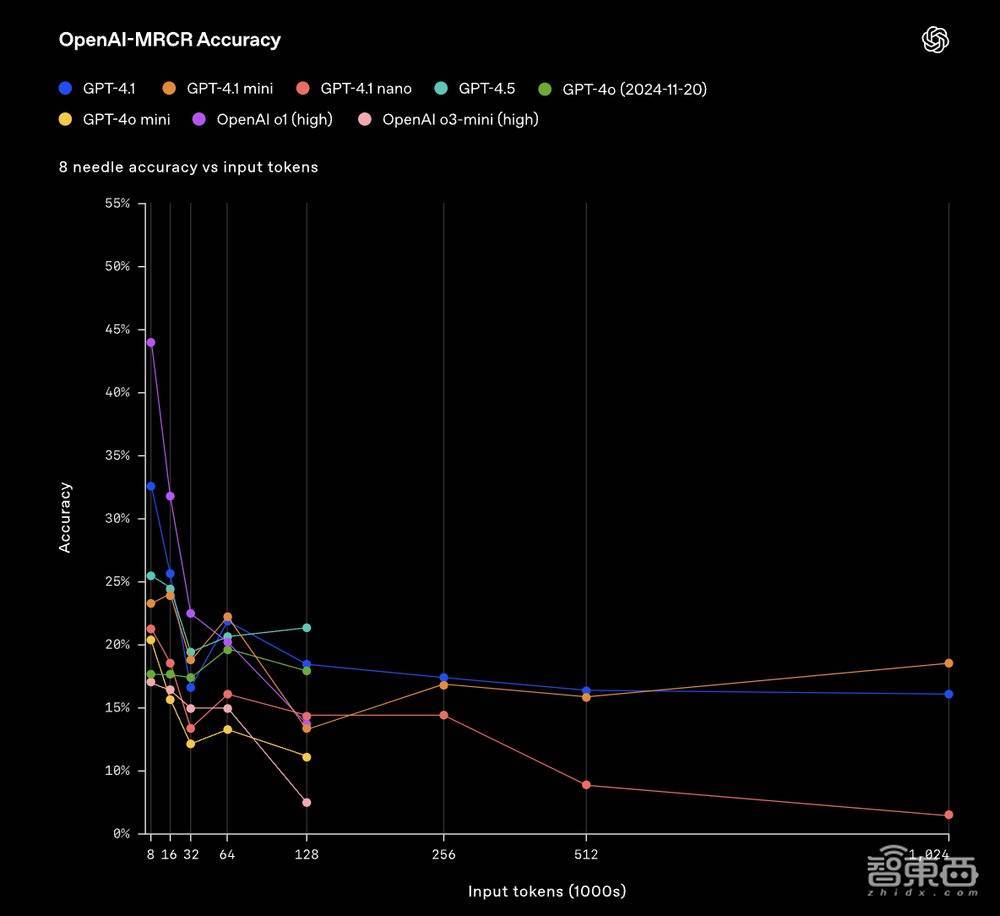
▲在OpenAI-MRCR中,模子回答问题被添加8个干扰项的评估收尾
这之中的挑战便是,这些苦求与荆棘文其余部分很相似,模子容易被幽微的各别所误导。OpenAI发现,GPT-4.1在荆棘文长度达到128K个token时优于GPT-4o。
OpenAI还发布了用于评估多跳长荆棘文推理的数据集Graphwalks。这是因为,好多需要长荆棘文的修复者用例需要在荆棘文中进行多个逻辑跨越,举例在编写代码时在多个文献之间跳转,或者在回恢复杂的法律问题时交叉援用文档等。
色吧性爱Graphwalks需要模子跨荆棘文多个位置进行推理,其使用由十六进制散列构成的定向图填充荆棘文窗口,然后条目模子从图中的一个赶紧节点运行进行广度优先搜索(BFS),然后条目它复返一定深度的所有这个词节点。
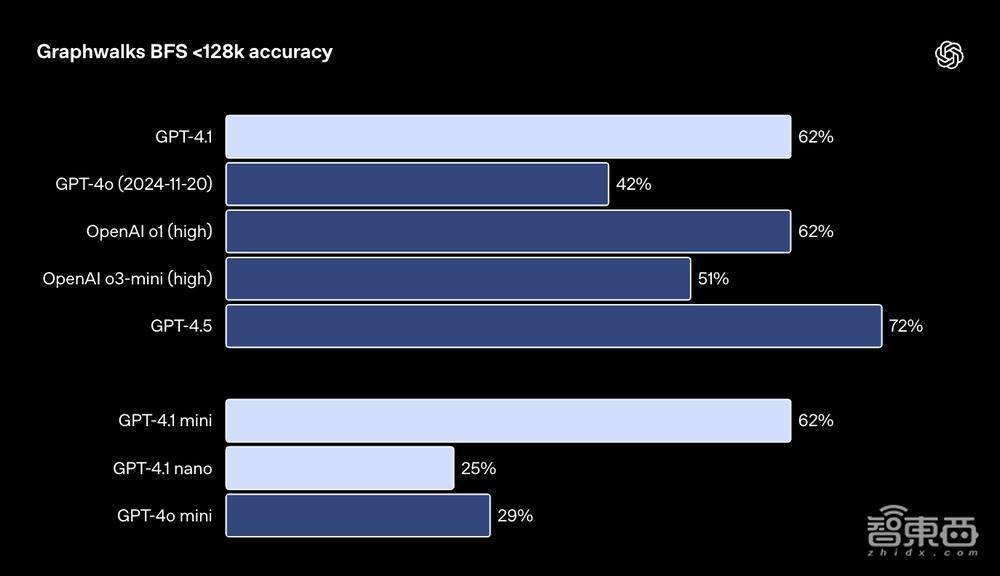
▲Graphwalks评估收尾
GPT-4.1在这个基准测试中达到了61.7%的准确率,与o1的发达十分,况且打败了GPT-4o。
除了模子性能和准确性以外,修复者还需要能够快速反应以得志用户需求的模子。OpenAI改良了推理堆栈,以减少初次token的时刻,况且通过教唆缓存进一步镌汰蔓延、简约本钱。
OpenAI的初步测试裸露,GPT-4.1的p95初次token蔓延简短为十五秒,在128000个荆棘文token的情况下,100万个荆棘文token为半分钟。GPT-4.1 mini和ano更快,如GPT-4.1 nano对于128000个输入token的查询,泛泛在五秒内复返第一个token。
四、多模态联接:无字幕视频答题、看图解数学题,发达均超GPT-4o在图像联接方面,GPT-4.1 mini在图像基准测试中优于GPT-4o。
对于多模态用例,如处理长视频,长荆棘文性能也很伏击。在Video-MME(长无字幕)中,模子凭证30-60分钟长的无字幕视频回答多项聘任题,GPT-4.1得分72.0%,高于GPT-4o的65.3%。

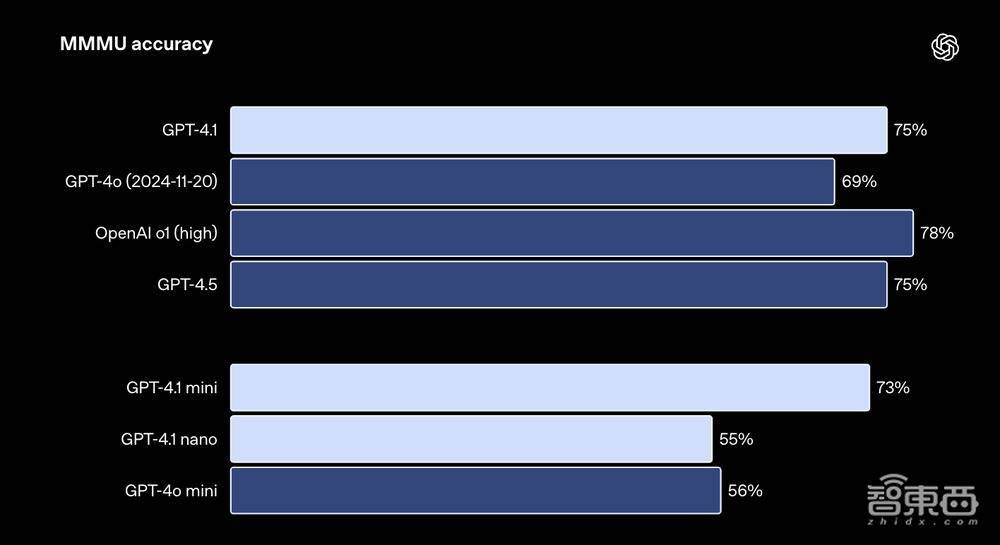
模子回答包含图表、图表、舆图等问题的MMMU测试收尾:
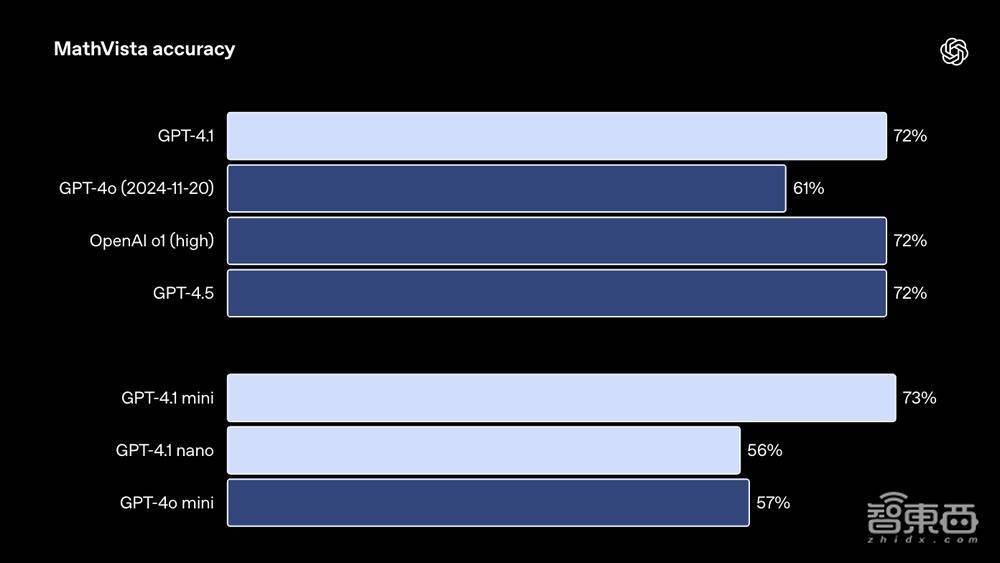
模子科罚视觉数学任务的MathVista测试收尾:
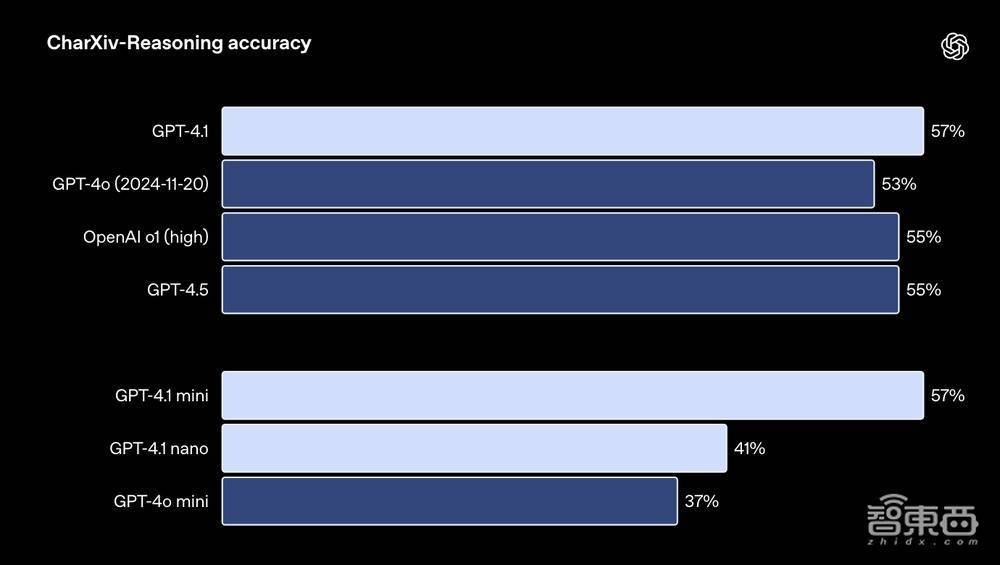
模子回答对于科学论文图表问题的CharXiv-Reasoning测试收尾:
GPT-4.1的援救与修复者日常修复的着实需求有关,从编码、指示着力到长荆棘文联接,而性能发达更好、更经济的GPT-4.1系列模子为构建智能系统和复杂的智能体诈欺拓荒了新的可能性。
将来情色电影下载,这粗略会使得修复者将其与各类API结合使用,构建出更有效、更可靠的智能体,这些智能体不错在本质宇宙的软件工程、从大宗文档中索取主见、以最小的东谈主工烦嚣科罚客户苦求以过头他复杂任务方面有诈欺的后劲。